A few weeks back, an article titled "Interactions Among Morphology, Word Order, and Syntactic Directionality: Evidence from 55 Languages" (henceforth: Li & Liu 2025) came across my link aggregators. It checked a few boxes for me: it had "word order" and "directionality" in the title, it promised to examine the interaction between word order/directionality and morphology using quantitative methods, and it used data from Universal Dependencies (henceforth: UD) treebanks. There's three of my major research interests right there, so I was very much hooked, but also suspicious; such studies tend to go two major ways and only one of them is a good one. It only took 8 pages for me to realize that this one will not fall into that group. More specifically, it was this part that gave me pause (Li & Liu 2025: 8):
"The Afro‑Asiatic Semitic family exhibits distinct word order preferences. Arabic and Maltese strongly favor verb‑initial (VSO) patterns (about 70%), reflecting a consistent syntactic profile."
The data underlying this observation comes from the Maltese UD treebank, i.e. MUDT, as Table 1 of the paper (reproduced partially below) confirms.
| Language/Data | Type | SVO(%) | SOV(%) | VSO(%) | VOS(%) | OVS(%) | OSV(%) |
|---|---|---|---|---|---|---|---|
| Arabic | (PUD + NYUAD) | 18.1 | 0 | 72.8 | NA | 3.9 | 0.2 |
| Maltese | (MUDT) | 24.1 | 0 | 69.9 | NA | 4.1 | 1.9 |
Now I am somewhat familiar with MUDT, seeing as I manually annotated the whole damn thing and then used it to get my PhD. In fact, a significant portion of my dissertation was dedicated to doing the exactly this kind of analysis - except I speak of "constituent order" - and my results were completely different. To compare, consider Fig. 7.5 and Tab. 7.5 from p. 190 (click to embiggen).
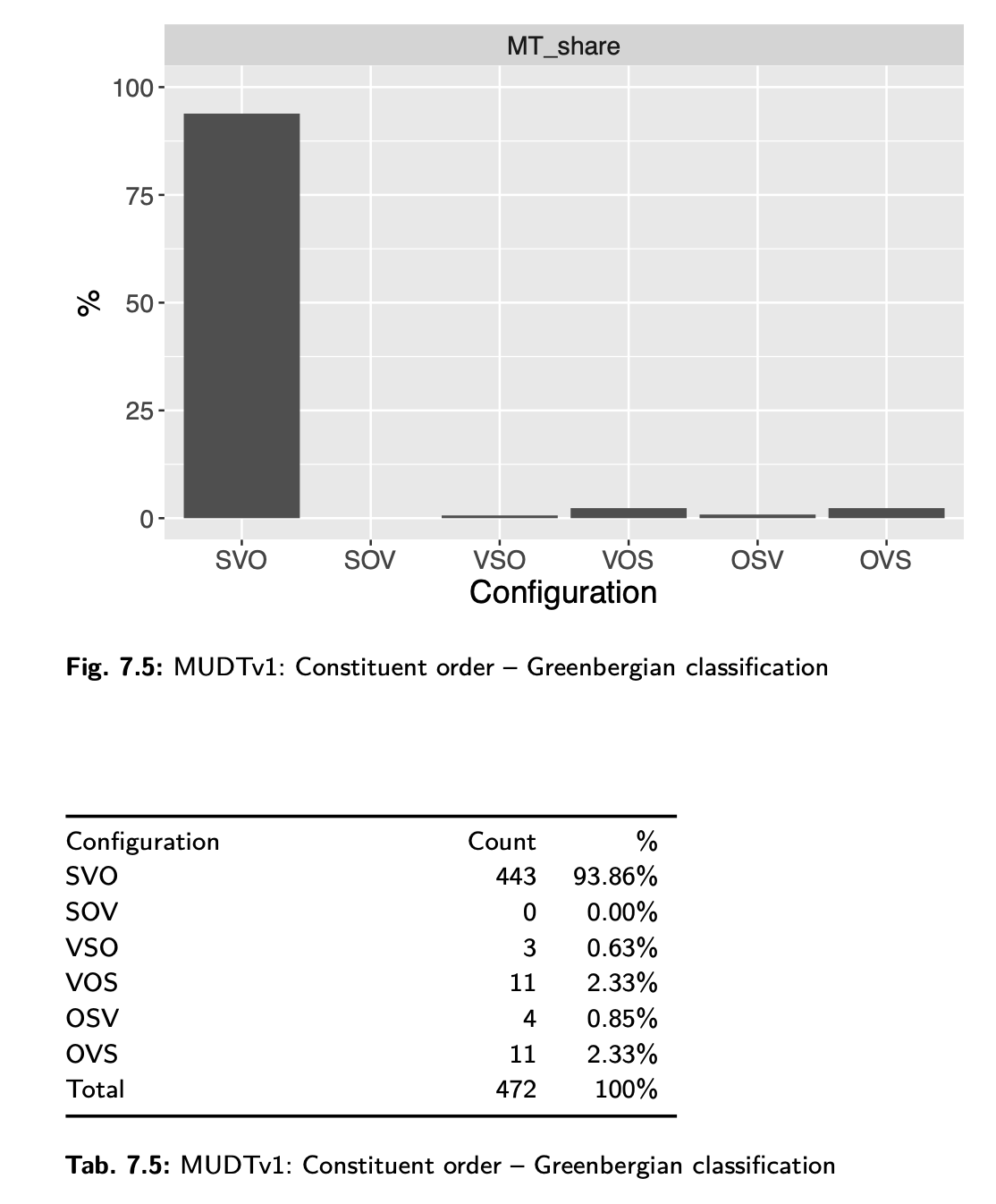
Even if we focus just on the dominant order - or linearization, as Li & Liu (2025: 4) call it in line with common practice - the difference is striking: Li & Liu 2025 have 24% for SVO and 70% for VSO. In my analysis, VSO is nearly non-existent: only 3 sentences show that order (see p. 190); the vast majority of sentences (93.86%) exhibit SVO order.
So what giveth? It is of course, entirely possible that I was wrong, but surely I wasn't THAT wrong. Let's try to find out what happened and we might as well start with how Li & Liu got their numbers. And this is where we come across the first problem: they don't say. All we learn in the paper is that
"All metric computations and statistical analyses, including correlation tests between variables, were implemented using the Python programming language (version 3.11)."
(Li & Liu 2025: 3)
and
"Our Python‑based tool extracts these linearizations directly from dependency structures, allowing the analysis to accommodate varied syntactic patterns and reflect actual language use."
(Li & Liu 2025: 4)
and finally
"All metrics and values reportedin this study were computed independently using custom scripts developed by the authors."
(Li & Liu 2025: 12)
The code, however, is nowhere to be seen. Red flag number one.
OK, fine, ORANGE flag, because to be fair, my data retention practices are not perfect either. The data I used is available online along with the text of the dissertation, but the instance of Annis I used to run queries on the treebank has gone to the eternal filesystem beyond. Then again, the queries I used are fully available online as Appendix C, so once I get Annis running again - or you do - all is good and my work can be fully reproduced
Except here's an issue: the treebank I used in my dissertation was UD version 1 and while it was current when I started annotating, by the time I finished, version 2.1 had come out. Li & Liu (2025) write in 2025, by which time versions 2.15 and 2.16 were out. By that point, I had also updated MUDT to the current version, so we just need to find out which one they used...
And here we have orange flag no. 2: they do not say. All we learn is that
"The raw data used in this study are openly available from the UniversalDependencies (UD) treebanks at https://universaldependencies.org."
(Li & Liu 2025: 12)
At the beginning of their paper, Li & Liu inform us that
"To ensure consistency and cross‑linguistic comparability, all treebanks in this study employed the Universal Dependencies (UD) annotation framework [15]. "
(Li & Liu 2025: 3)
Maybe the reference behind [15] will tell us. Well, no, it does not, since it leads to J.A. Hawkins's Efficiency and Complexity in Grammars. Reference [17] which is supposed to point to a work by Xanthos and Gillis points instead to De Marneffe et al. (2021) which is a paper on UD, so maybe stuff just got mixed up. De Marneffe et al. 2021, however, is a general description of the framework, so alas, no info on the version here either. Also, nobody noticed this mix-up? Orange flag no. 3.
Let us therefore assume that Li & Liu (2025) used the most recent version available to them, 2.16. As of this writing, the current version is 2.17, but I am reliably informed by the portly gentleman who brushes my teeth that there were no relevant changes between the versions, so let's go with 2.17. And since we are dealing with a single treebank, we don't have to write any custom code or even deal with Annis; the fastest way to access any UD treebank in 2026 is to use grew-match.
Y'all know how dependency grammars work: an utterance/sentence consists of tokens (≈ words) where each token is a dependent of another token, called the governor. There is one exception: in every utterance/sentence, there is a token - prototypically a verb - that does not depend on any other token; we call it the root. The relationship between the governer and a dependent is referred to as a dependency and it can be unlabeled or labeled. In UD, all dependencies are labeled according to a specific framework and as a shorthand, the dependencies are referred to by their label.
grew-match is a graph-based search engine for treebanks which allows the user to search for all kinds of things. It works with nodes (= tokens) and edges (= dependencies). It is powerful, but the query language can be a bit tricky, so let's look at an example:
pattern { V -[nsubj]-> S;
V -[obj]-> O }
Here we have three nodes, V, S, and O. They are connected to each other as follows: S depends on V and the dependency label is nsubj (= nominal subject), O depends on V through the dependency obj (= object). In other words, this looks for clauses where we have a Subject, Verb (or any other predicate) and Object. We could further specify what kind of part-of-speech V should be, but in UD, if it has an object, it is a verb, so let's keep it at that.
Now if you ran the query like I just did, grew-match would report "395 occurrences". This means that there are 395 sentences total where we have a transitive verb with both an overt subject and an overt object. This is consistent with the findings in my dissertation (p. 190, see above), with one caveat: MUDT annotation contains one more dependency that I treat as a direct object for purposes of constituent order analysis, namely obl:arg. This covers prepositional objects and it exists as a separate category for compatibility purposes (don't get me started). If we include it in our query like so
pattern { V -[nsubj]-> S;
V -[obj|obl:arg]-> O }
we will get 473 results which matches the data above perfectly (modulo fixes between v1 and v2).
The queries we have used so far do not take into account the order of the constituents and so for example, the third hit is an OVS sentence (sentence id 02_02J01:10). To consider the order, we adjust the query as follows:
pattern { V -[nsubj]-> S;
V -[obj|obl:arg]-> O;
V << S;
S << O }
The double "less than" sign specifies the order of nodes; in this case, V should come before S and S should come before O. This query will thus retrieve all VSO sentences in the treebank. Recall that according to Li & Liu (2025: 8), this should be 70% of all sentences with V, S and O; according to my analysis, we should get 3.
And lo and behold, 3 sentences is what we get. Go ahead, try all the permutations, it will more or less be the same as in my dissertation.
So, I repeat, what giveth? Well, we have already seen three orange flags that point to a certain degree of sloppines on the authors' part, so let's... Hang on just a minute, what is the name of the journal this was published in? Entropy? What kind of a name is that for a ling...
"Entropy is an international and interdisciplinary peer-reviewed open access journal of entropy and information studies, published monthly online by MDPI."
And now everything clicks into place and you will excuse me while I recover from the dizziness induced by the huge amount of red flags suddenly unfurled in front of my eyes.
For those of you not in the know, MDPI is a paper mill and predatory publisher. I will not dwell on the predatory part, just point out the following: every journal published by MDPI levies an article processing charge of 2600 CHF (2850 EUR).
The paper mill part is much more interesting. As of this writing, MDPI publishes 511 open access journals. This is on par with Oxford University Press, but much less than Springer, so that might not be suspicious. But let's take a closer look, for example at Entropy: it is the end of March 2026 and they have already published three issues of volume 27 containing 362 articles. That's four PEER REVIEWED articles a day, including holidays. One analysis of MDPI's production refers to "concerns about how peer review can be conducted effectively at this scale". That's putting it mildly.
To answer my question above, what giveth is that a) the authors of the paper are incompetent and b) there was no peer review to catch their incompetence. No one at MDPI cares as long as they pocket their 2600 CHF.
Incidentally, the aforementioned analysis focuses on the proliferation of "special issues" which allows the publisher to expand the number of articles published and thus their revenue. It turns out that Entropy published a special issue titled "Complexity Characteristics of Natural Languages". This special issue was edited by the same people who appear as "Academic Editors" (what the hell is even that) for the bullshit word order paper: Stanisław Drożdż, Jarosław Kwapień and Tomasz Stanisz. None of them is a linguist, they are all physicists and work at the Institute of Nuclear Physics of the Polish Academy of Science. They appear to be interested in what they call "quantitative linguistics" but what would better be described as "applying mathematical methods to texts". And don't get me wrong, this is a legitimate field of research, but maybe the gentlemen in question should devote more time to studying linguistics proper sparing us insights such as (emphasis mine)
"During their development languages have been gradually reshaping and adopting themselves under influence of other languages and dialects they have encountered. Especially English and Spanish experienced many of such encounters. Whether this made them as they are or they became global because they happen to possess some spontaneously acquired favorable intrinsic syntactic organization emerges an exciting issue for further interdisciplinary explorations."
"We found that although the global behaviour of words is described approximately by the Zipf-Mandelbrot law, the words from different parts of speech do not necessarily follow this global picture and one can show significant differences in functional dependence of frequency on rank between nouns, verbs and other types of words. This can be a manifestation of the existence of a non-trivial internal organization of language that cannot be reproduced in full detail by a simple power-law relation of the Zipf-Mandelbrot type."
Whether such a conclusion is worth the effort put into it, I will leave to the reader, accompanied by the appropriate XKCD comic (h/t a colleague who shall remain unnamed).

In any case, Messrs. Drożdż, Kwapień and Stanisz should be ashamed of their role in the predatory practices of MDPI in general and of this bullshit paper in particular.