We all know the about of how the kangaroo got its name: one of the English sailors (or even Cook himself) asked a native what that strange creature was called and the native replied "gangarru" (or some such) which was then adopted as the name for the creature and which later turned out to mean "I don't understand". We all know that this story is, of course, a myth.
So earlier today I was reviewing the data for the publication of a paper I and Stéfano presented at the 2024 conference of the Association Internationale de Dialectologie Arabe. The paper is a pilot study of sorts, attempting a phylogenetic analysis of Arabic varieties. The idea - adopted from biology - is to treat the varieties as taxa and selected linguistic features as nucleotide sequences or some such. Then you just annotate the data, plug it into one of the standard applications and presto! you got yourself a nice visualization of the relationship between the varieties, maybe even some Bayesian modelling of the same. It has been done before, e.g. for creole languages, so it makes perfect sense to try to do it for Arabic. Doubly so if there has recently been a survey of linguistic features of Arabic varieties and the authors have provided you with the raw data. A bit of Python jiggery-pokery and William's your mother's male sibling.
Famous last words.
I do not mean to disparage Manfred Woidich and Peter Behnstedt (may he rest in peace) in any way, their four-volume Wortatlas der arabischen Dialekte is a monumental achievement in Arabic dialectology. Plus let's face it, data management is not easy under the best of conditions, let alone with linguistic data of this type. It is true though that even with the raw data underlying the Wortatlas at one's fingertips, wrangling the data into shape is a complicated endeavor. For one, there were issues of technical nature, where all the data were stored in one of them God-forsaken ante-diluvian formats. The export worked, but since the Arabic text was stored in Odin-only-knows what encoding, the thousands of entries painstakingly recorded by Behnstedt are now lost to the ___???? hell, to say nothing of their attestations consisting of dead links to long-defunct internet fora painstakingly collected and annotated by Behnstedt. It is a giant loss and I hope the data is recoverable.
Then there's the nature of the data which, to be fair, reflects the practices of modern Arabic dialectology: the field is simultaneously is concerned with both the description of the current state of the variety in question AND history and relationship to other varieties; as a result, it often fails to do both properly. Take the the concept 'tomorrow' (item 460 in Wortatlas IV) where we learn that the corresponding words in modern varieties fall into three groups based on their root/etymology: root BKR (A), word ġudwah 'early part of the day' (B) and aṣ-ṣubḥ '(early) morning' (C). We then get lists of which derivations occur where, but without any indicaton as to what is the prevalent form. And so for example for Antiochia, the data set has both bikra (A) and ġadik (B). Which is it, which do I pick as THE form? And this is a simple example, it gets a whole lot more difficult with other lexical items.
And speaking of Antiochia, what do even take as taxa? All of you have surely noticed that while in the description of the entire endeavor I referred to Arabic varieties, in the previous paragraph, I discussed the practices of Arabic dialectology. As I once (before nuking my Twitter account) tried to explain to an idiot, in Arabic linguistics, we use the term 'dialect' for historical, political and sociolinguistic reasons for what in Romance, Slavic or Germanic linguistics we would call separate languages belonging to the Romance (Slavic, Germanic...) branch of Indo-European. So yes, it would be more appropriate to speak of Egyptian, Tunisian or Yemeni, except... Well, all of them co-exist in a special relationship with Modern Standard Arabic and, more importantly, there is no one/dominant/prevalent/okfineiwillsayit standard variety of, say, Moroccan or Iraqi in the same way that there is a dominant/prevalent/cmonpeopledontmakemesayitagainFINE standard German, Polish or French. And so in, say, Egypt, Cairo Arabic may be what people think of when they think of Egyptian, but there are other subvarieties of the Egyptian variety which are just as important and who is to say which is THE Egyptian, surely not the assholes in Cairo! So yes, Lebanese, why not, but then not just one.
Which brings me to the actual question: how do you divide the varieties? The prototypical way to do it in any dialectology is go by a location, except those range from entire regions through towns and villages, all the way to neighborhoods. But this is Arabic dialectology, so we have tribal varieties, confessional varieties and the specter of bedouin varieties hanging over the whole thing. And on top of that, there is the fact that despite literally centuries of Arabic dialectology, there are only handful of Arabic varieties that are actually well described. Sure, you can throw a metaphorical stone and metaphorically hit a book on this or that Arabic variety that bills itself as a grammar. Upon closer reflection, however, you will find that they contain a detailed description of phonology and morphology, but little to nothing on syntax. And then there's of course the aforementioned issue with the raw data underlying Wortatlas where the "place" (roughly our "taxon") column sometimes has the present-day country name like, "Sudan" (or "Usbekistna"), sometimes a region like "Ḥaḍramawt" or "Sinai" or even "Trucial Coast", sometimes a country with a placename, e.g. "Sudan/Šukriyya".
So in the end, we made a decision to focus on
- A selection of function words from Wortatlas IV (= features), 35 in total. These contain such items like 'who', 'what', 'when', 'never', 'yes' and the existential predicate, each of them bearing a three-digit code that starts with 4.
- 63 varieties where we could get the data for at least 15 of the features (= taxa).
The taxa were arranged by - mostly - country: AF = Afghanistan, AL = Algeria, BH = Bahrain, CH = Chad, EG = Egypt, IL = Israel, IN = Iran, IR = Iraq, JO = Jordan, KN = Kinubi (that's the 'mostly' part), KU = Kuwait, LB = Lebanon, LY = Libya, MK = Morocco, MT = Malta, NG = Nigeria, OM = , PL = Palestine, SA = Saudi Arabia, SU = Sudan, SY = Syria, TR = Turkey, TU = Tunisia, UZ = Uzbekistan and YE = Yemen. Where data was available for a particular village/region/tribe, the taxon was named XX-<village/region/tribe>, where we only had data for the country, we labelled it XX-general. Then for each taxon, we gathered all the features, decided which to pick a representative one whenever necessary (always going with the more common option) and to each unique feature, we assigned a code. Sounds simple, but oh boy, was it not.
And so earlier today I was reviewing that data, now imported into EDICTOR, when I came across this entry:
'Tis weird, I thought, for item 473 is the existential predicate which is in most Arabic varieties derived from the preposition fī 'in'. The taxon here is Kinubi, a creolized variety which is admittedly very different, but surely not that different. So I checked the data and sure enough, there it was:
| es gibt | dé kalám táki má | Ki-Nubi | Ki-Nubi | QUEST |
The "QUEST" note means this piece of data came from a questionnaire. The lack of spaces in the EDICTOR entry is simply the result of normalization, so that is fine. Or, well, not actually, because normally the data would not have this many spaces and anyway this looks like a full sentence and besides, that last word looks like negation... So I went in and checked a bunch of sources and turns out it is a sentence:
dé kalám tá-ki má
this word/thing POSS-2SG NEG
'this is not your word/thing'
I have no idea how this ended up in the data considering the existential predicate in Kinubi is, unsurprisingly, fí. Perhaps this particular sequence of words has an idiomatic meaning in Kinubi, something like 'we don't say that'. Perhaps someone wasn't paying attention. In any case, this, ladies and gentlemen, is how we almost ended up with a version of kangaroo in our phylogenetic analysis. You know what, maybe I should keep it in, as a trap street of sorts, to keep reviewers on their toes.
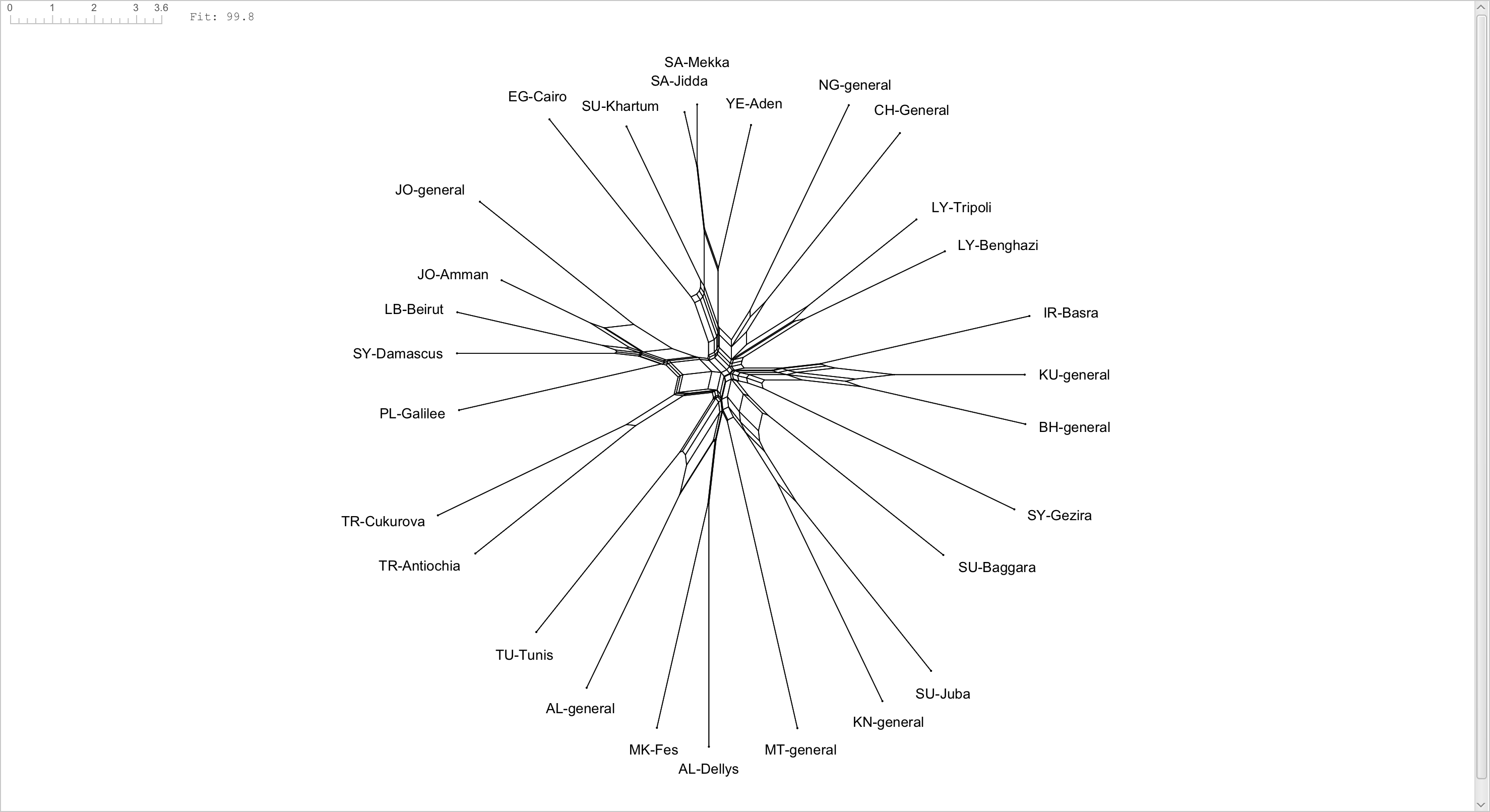
In case you're wondering what we came up with, below is a preview consisting of only 28 taxa (click to embiggen). The main take-away is that by Jove, it works, or at least that the basic NeighborNet algorithm matches what we would expect. For example, there are clear groupings of North African (6-7 o' clock), Levantine (9-10 o'clock) and Iraqi and Gulf (3 o'clock) varieties. Kinubi and Juba, another creolized variety, go together (and are not that far from Baggara), as do Egyptian and Sudanese varieties. Maltese, of course, stands on its own.
For more, watch this space. But now, back to data wrangling.